声明:本文来自于微信公众号 尹晨带货实录(ID:yinchen8810),作者:尹晨,授权转载发布。直播三年,做了很多号,也死了很多号,在过去的时间中,从算法、人货场、运营、数据等不同板块,总结超过了
服务器端缓存失效的应对方法经验总结
互联网
2022-03-21 17:14:48
133
缓存失效情况举例
看下这个段伪代码:
local value = get_from_cache(key)
if not value then
value=query_db(sql)
将_设置为_缓存(值,超时=100)
end
return value
这似乎没有问题,单元测试也不会有例外。
但是,进行压力测试的时候,你会发现,每隔100秒,数据库的查询就会出现一次峰值。如果你的cache失效时间设置的比较长,那么这个问题被发现的机率就会降低。
为什么会出现峰值呢?想象一下,在cache失效的瞬间,如果并发请求有1000条同时到了 query_db(sql) 这个函数会怎样?没错,会有1000个请求打向数据库。这就是缓存失效瞬间引起的风暴。它有一个英文名,叫 "dog-pile effect"。
怎么解决?自然的想法是发现缓存失效后,加一把锁来控制数据库的请求。具体的细节,春哥在lua-resty-lock的文档里面做了详细的说明,我就不重复了,请看这里。多说一句,lua-resty-lock库本身已经替你完成了wait for lock的过程,看代码的时候需要注意下这个细节。
为了提高业务访问速度和读取并发性,许多用户将在业务体系结构中引入缓存层。服务的所有读取请求都被路由到缓存层,通过缓存的内存读取机制,服务读取性能大大提高。缓存中的数据无法持久化。一旦缓存异常退出,内存中的数据就会丢失。因此,为了保证数据的完整性,企业更新后的数据将登陆到数据库等持久性存储中。目前,云用户的业务架构大致如下:

在上图中,您可以看到用户的更新数据被直接持久化到数据库中,业务读取请求直接请求缓存的数据。因此,业务需要解决缓存失效问题,即数据变更导致缓存中数据失效的问题。目前,解决缓存失效问题的方法是实现数据库和缓存的双写。要通过业务双写解决缓存失效问题,存在以下问题:
代码侵入性比较强,需要双写两份存储,任何对DB的数据变更,都需要同时更新缓存,代码层面后期可维护程度不高
用户请求线程里同步调用缓存,对缓存存在强以来,遇到缓存超时等异常时,没有办法做到有效的重试,遇到异常给用户返回系统错误、操作失败等信息,严重影响用户体验
用户请求线程里同步完成DB、缓存双写,变更请求链路长,访问延迟大,影响用户体验
RDS数据订阅消费,轻松解决缓存失效
阿里巴巴也遇到了缓存失效的问题。随着业务架构的不断调整和优化,我们沉淀了一套高度可靠、优雅的缓存失效架构。即通过数据传输提供的数据订阅功能,异步获取DB的增量数据(如公共云上的RDS),并根据增量数据使缓存失效。具体架构如下图所示:
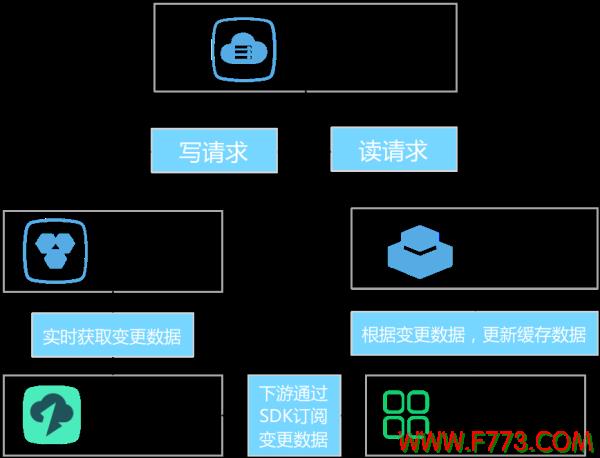
在这个架构里面,缓存更新流程如下:
1.业务完成DB更新后即返回请求
2.数据订阅通过日志解析方式实时解析并订阅DB的增量更新数据,当发现DB有数据更新时,将增量数据推送给下游消费者
3.一旦下游使用者服务接收到增量更新数据,它就会调用使用者线程来更新缓存
至此完成整个缓存更新过程。
从上面的缓存失效过程中,我们可以看到这种缓存失效机制:
1.更新路径短,延迟低:缓存失效是一个异步过程,在业务更新数据库后直接返回。无需关心缓存失效过程。整个更新路径短,更新延迟低
2.应用简单可靠:应用无需实现复杂双写逻辑,只需启动异步线程监听增量数据,更新缓存数据即可
3.应用更新无性能消耗:因为数据订阅是通过解析DB的增量日志来获取增量数据,获取数据的过程对业务、DB性能无损
小结 数据订阅功能为阿里云数据传输提供的一种数据分发方式。通过数据订阅实现的缓存失效策略,让业务更新更快捷,让业务逻辑更简单、更可靠。
数据订阅只是数据传输提供的一种传输方式,除数据订阅之外,数据传输还提供了数据实时同步,不停服迁移等多种传输能力,如需了解数据传输更多详情,请猛击数据传输。
相关文章
-
25
2023-02
-
17
2022-11
-
17
2022-11
-
04
2022-05
-
04
2022-05
-
27
2022-03
推荐阅读

随机推荐
- iPhone 13 Pro最新外观和价格曝光:有望支持无线反向充电
- 好看视频悄悄测试“写标签”功能进一步打开百度内容生态
- 东京奥运会倒计时7月8日中国女排奥运会出征“首场演出”登陆快手
- 腾讯宣布深夜向河南捐赠1亿韩元救援物资支援受灾地区
- 在线教育群消失:98.5%的考生离职
- 联想集团董事长兼CEO杨元庆:未来不排除自主研究芯片的可能性
- 小米汽车总部 家工厂已经基本决定落户北京
- 努比亚预告了65W 4端口氮化镓充电器 到目前为止体积最小
- 迄今为止更大的升级!新款iPad mini上架:全屏幕 支持5 G
- 作者的最新文章
- 用基础创新杠杆煽动产业数字化:产教融合鲲鹏答案
- 供应商爆料正为苹果研发潜望式变焦镜头:最快在iPhone 14上搭载
- 回到“代码”的文科生
- 董明珠成立预制蔬菜设备公司;启动云游戏不再免费赠送周小时;五菱MINIEV敞篷车价格公布
- 百度地图发布2022国庆出行预测:预计10月1日10:00-11:00将出现高速拥堵高峰
- 梅西计划通过一家新的硅谷控股公司进入科技投资领域
- 马斯克 辞职?马斯克凭什么能拿3600亿高薪 律师回应:他不是一般CEO
- 腾讯Q3营销宣传费同比减少32% 完善经营 提高效率
- Gome否认破产清算腾讯游戏管家PC端将停止;魔兽世界开通临时充电频道
- 李想 one:李想:最理想的计划是2024年推出基于大比例模型、覆盖所有城市的NOA