DeepMind发布强化学习通用算法DreamerV3 艾城静自学Dia
内容一览:强化学习是多学科领域的交叉产物,其本质是实现自动决策且可做连续决策。本文将介绍 DeepMind 最新研发成果:扩大强化学习应用范围的通用算法 DreamerV3。关键词:强化学习 De
顺晟科技
2023-02-23 11:52:06
101
内容摘要:加强学习是多学科领域的交叉产物,其本质是实现自动决策,能够持续决策。本文介绍了DeepMind的最新研究开发结果:DreamerV3,这是一种用于加强学习应用程序的通用算法。
关键词:强化学习DeepMind通用算法北京时间1月12日,DeepMind官方推特,官方官方宣传DreamerV3,游戏& amp# 039;我的世界& amp# 039;在中,在不参考人类数据的情况下,从一开始就可以开始收集钻石的第一个通用算法得到了解决。
DeepMind在Twitter上将DreamerV3强化学习扩大为问题,开发需要普通算法强化学习,计算机使Alpha GO能在围棋比赛中战胜人类,OpenAI Five能在Dota 2中战胜业余玩家,从而通过交互解决某些任务。

OpenAI Five在比赛中是人类玩家R & ampamp战胜d队,和人类玩家合影。
但是,要将算法应用于新的应用场景,如从棋盘游戏移动到电子游戏或机器人操作,工程师必须不断开发特殊算法,如连续控制、稀疏补偿、图像输入、空间环境等。
这需要大量的专业知识和计算资源来微调算法,极大地阻碍了模型的扩展。在不进行调谐的情况下,创建熟悉新domain的通用算法成为加强学习应用领域和解决决策问题的重要方法。
因此,DeepMind和多伦多大学共同开发的DreamerV3应运而生。
DreamerV3:基于标准模型的通用算法DreamerV3是基于标准模型(World Model)的通用、可扩展算法,以固定超参数为前提,可应用于广泛的域(domain),比特殊算法要好。
这些域包括连续动作和离散动作、视觉输入和低维输入、2D和3D世界、不同的数据预算、报酬频率和报酬规模。
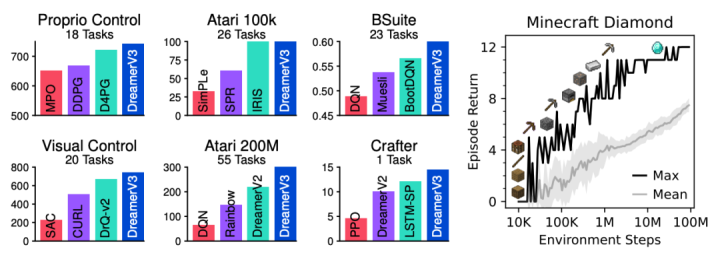
DreamerV3一般算法和特殊算法的性能比较DreamerV3由三个神经网络组成,这些神经网络在“重放体验”(replayed experience)中同时训练,并且不共享渐变。
1、世界模型:预测潜在工作的未来结果
2、critic:判断每种情况的值。
3、actor:学习如何使有价值的情况成为可能。
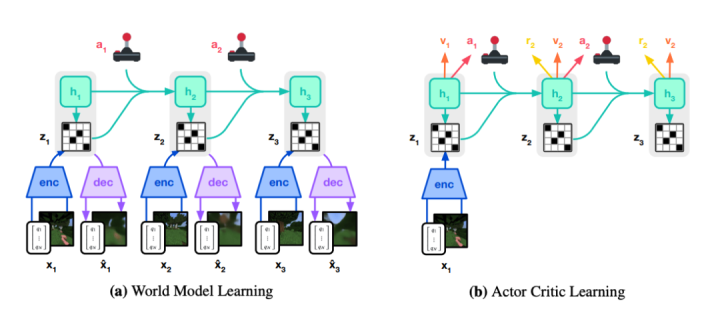
DreamerV3培训课程
如上图所示,world model将sensory input编码为离散表象ZT。Zt是在具有recurrent state ht的序列模型中预测的,并提供了运动at。Input被重组为学习信号,并被定性为shape。
Actor和critic在world model预测的抽象表象trajectory中学习。为了更好地适应跨域操作,这些组件必须适应不同的信号强度(signal magnitudes),并在目标内稳定地平衡terms。
工程师在超过150个固定参数的任务中测试了DreamerV3,并与文献中记载的最佳实践进行了比较,DreamerV3提高了domain在不同任务中的通用性和可扩展性。
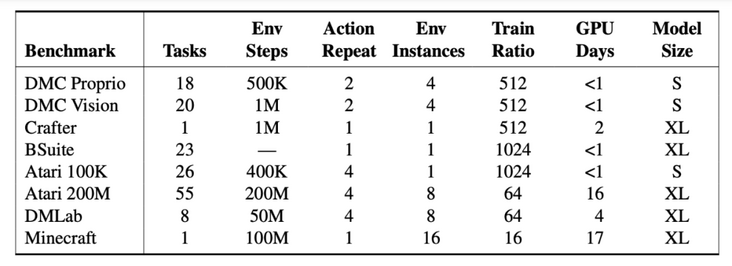
基准概述所有代理都在NVIDIA V100 GPU上培训了DreamerV3,在7项基准测试中取得了优异的成绩,并在state和image的continuous control、BSuite和Crafter中设置了新的SOTA级别。
但是,DreamerV3仍然存在局限性。例如,当环境steps在1亿以内时,算法不是像人类玩家一样在所有场景中捡钻石,而是偶尔捡回来的。
站在巨人的肩膀上回顾Dreamer家族发展史。
世代:Dreamer发布日期:2019年12月
参与机构:多伦多大学、Deep Mind、Google Brain
论文地址:https://arxiv.org/pdf/1912.01.
算法简介:
Dreamer是一个强化学习代理,只能通过代理映像解决图像中的长区域操作。
基于模型预测的反向传播,利用世界模型进行高效的行为学习。在20项要求苛刻的视觉控制任务中,Dreamer在数据效率、计算时间和最终性能方面超过了当时的主流方法。
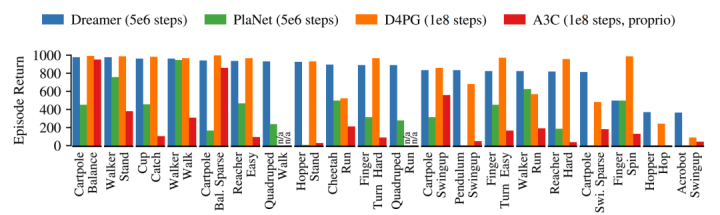
Dreamer与当时主流方法的性能比较Dreamer继承了PlaNet的数据效率,超过了当时领先的model-free agent的渐近性能(asymptotic performance)。5x106 environment step之后,Dreamer在每项任务中平均性能为823,而PlaNet只有332,最高的model-free D4PG agent在108阶段之后为786。
第二代:DreamerV2发布:2020年10月
参与机构:Google Research、DeepMind、多伦多大学
论文地址:https://arxiv.org/pdf/2010.02.
算法简介:DreamerV2是一款增强的学习代理,可从world model紧凑的隐形空间预测中学习行为。
注:这个世界模型使用离散表象,与战略分开训练。
DreamerV2是在单独训练的world model学习行为,从而在Atari基准的55个任务中达到人类水平的第一个代理。在相同的计算预算和wall-clock time方面,DreamerV2达到2亿帧,最高可超过单GPU代理IQN和Rainbow的最终性能。
DreamerV2还适用于学习复杂人形机器人的world model,以及具有连续动作的任务,以解决只用像素输入站立和行走的问题。
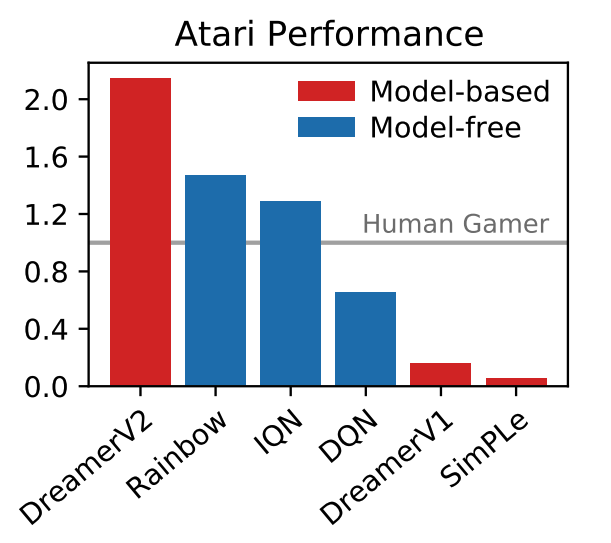
玩家在以Atari为基准的55个游戏的规范化中间分数中得分。
Twitter网友评论区以身作则,对于Deepmind Twitter V3的诞生,很多网友也在Deepmind Twitter评论区抖机灵。
解放人类,不再& ampquot我的世界& ampquot不需要。
不要爱玩游戏,做点正事吧!@DeepMind和首席执行官Demis Hassabis 
& ampquot我的世界& ampquot终极老大马永龙瑟瑟发抖。近年来的游戏& amp# 039;我的世界& amp# 039;成为强化学习研究的焦点& amp# 039;我的世界& amp# 039;在举行了多次收集钻石的国际大会。
人们普遍认为,在没有人类数据的情况下解决这个问题是人工智能的里程碑。因为在这个程序生成的开放世界环境(open-world environment)中,奖励少、探索困难、耗时长,而且由于这些障碍的存在,以前的方法都必须以人类数据或教程为基础。(约翰f肯尼迪)。
DreamerV3从0开始& amp# 039;我的世界& amp# 039;是第一个完全自学DIA收集的算法,进一步扩大了强化学习的适用范围。正如网友所说,DreamerV3已经是成熟的通用算法,学会自己挂机升级,与终极BOSS最后一条电影龙对抗。

23
2023-02
22
2023-02
09
2022-11
06
2021-11
06
2021-09
19
2021-08
