在日常生活中下载电视剧后导入手机、Pad中看,因文件名特别长不利于查找电视剧顺序,需要对文件进行批量重命名. 例如:将文件夹中所有的文件名的“【www.oicqzone.com】逃出克隆岛
用Python找到更赚钱的基金
顺晟科技
2021-06-16 10:44:01
220
关于基金分析这个小项目,我写过两篇文章,篇是思考,第二篇是实际工作,现在最后一篇是数据分析。其实第四条是视觉数据。数据可视化是一种艺术活动。以后我会写数据可视化。今天我主要带领大家分析一下基金数据,看看哪只基金能让你赚到最多的钱。毕竟投资理财才是王道。小伙伴们,一起探索吧~ ~
步:读取数据并了解数据
在上一篇文章中,我们在CSV文件中保存了6500多笔资金,这是一个很大的表格数据。先看数据,初步了解一下
a)。读入CSV文件
df=pd.read_csv(文件)
b)。看看有多少资金
打印镜头(df)6548
c)。熟悉数据格式,查看行和列中的信息
print df . indexrangeindex(start=0,stop=6548,step=1)print df . columns index([u ' fund _ id ',u'fund_name ',u'one_month ',u ' third _ month ',u'six_month ',u'one_year ',u ' third _ year ',u'from_start'],dtype=' object ')
d)。看看表中的前5只基金
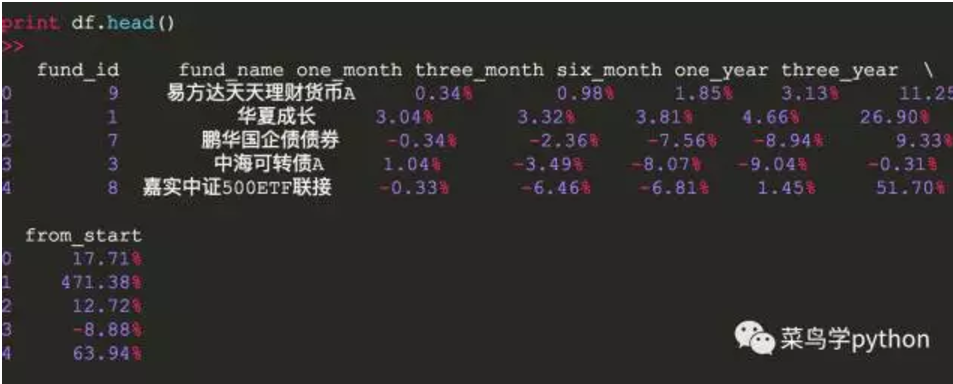
经过以上三步,我们已经知道这个大表数据是6549行*8列,其中:
索引是一个从0到6548的整数
基金标识是基金的标识
基金_名称一栏全是汉字
其他列是带百分号的数字字符串
我们处理这样的串行数据会有一些麻烦,比如:
指数不是基金id,所以很难统计
增量是一个带百分号的字符串。如何排序和计数
如何做横向统计,每行既有fund_name的汉字,又有的数字,如何总结
这三个问题怎么解决,我们往下看
第二步:数据清洗
1).先把index换成基金的id
以fund_id为索引,方便后期处理,会方便很多。在数据框中使用set_index函数
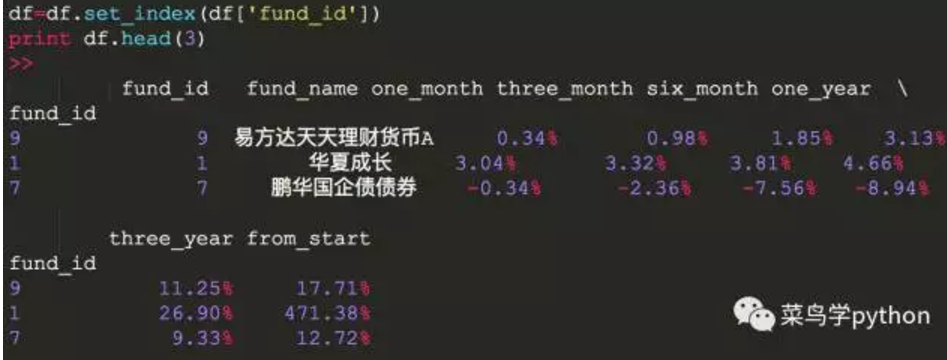
2).看看index是不是已经换了
3).去掉NA行
表中有很多空数据,这将影响我们的分析,我们必须删除它
#去掉NA的线
df2=df . drop na()print ' drop na column : ',len(df2)dropna column: 6315
4).去掉fund_name
为什么要去掉fund_name?例如,我们想计算一个基金成立以来的1个月、3个月、6个月、1年、3年的总和,看看它的总分是多少
直接求和有一个问题,就是fund_name是字符串,我们先删除fund_name,再删除fund_id的列,因为index已经是fund_index了,就不重复了。
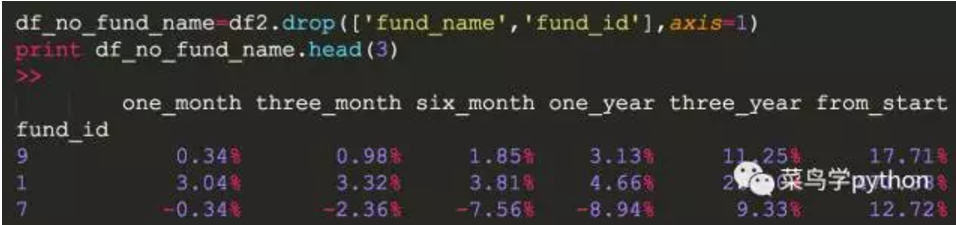
这种数据干净清爽多了吗
5).然后去掉%,我们就可以愉快地排序了
如何取消%,这次我们需要在熊猫中使用一个的应用函数
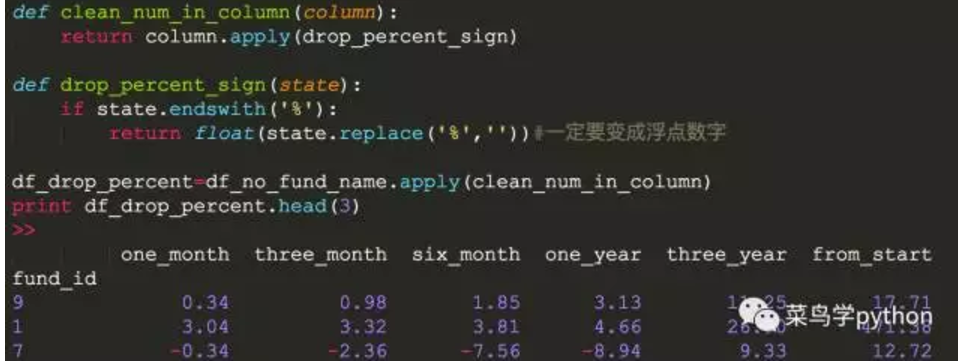
第三步:找出更佳投资基金
1).经过前面2步,已经万事俱备
换句话说,我们可以随意分析,先看顶卡情况,得到每一列的更大值,再看整个基金的顶卡情况。我们拿前100名
#获取‘from _ start’(根据基金成立以来增加的规模)
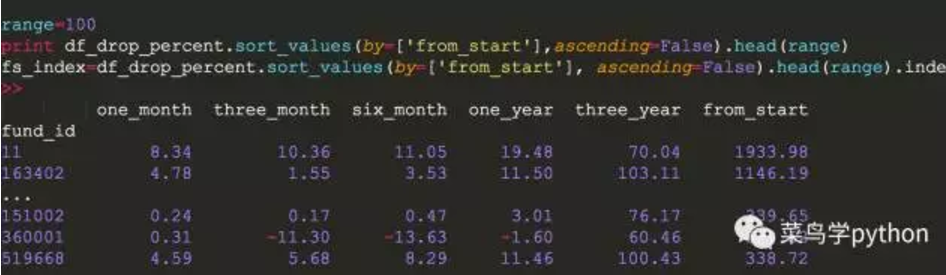
同样的道理,我们根据这个#得到了其他的顶卡,得到了printdf _ drop _ percent。sort _ values(by=[' third _ year '],升序=False)。head(range)y3 _ index=df _ drop _ percent . sort _ values(by=[' third _ year '],升序=false)。头部(范围)。索引#获得y1 _ index=df _ drop _ percent。sort _ values (by=['one _ year'],升序=false)。头部(范围)。指数#获得M6指数=df _ drop _ percent。sort _ values (by=['six _ month'],升序=false)。头部(范围)。指数#获得m3 _ index=df _ drop _ percent。sort _ values(by=[' third _ month '],升序=false)。头部(范围)。index #获得m1 _ index=df _ drop _ percent。sort _ values (by=['one _ month'],升序=false)。头部(范围)。指数
2).找出全能王中王
我们想知道是否在所有的投资组合中有最强的,就是从成立到现在一直在涨,涨了3年,1年,半年,3个月,1个月。这样的基金简直就是王中王。啊,有没有,怎么找?
#将以上所有索引转换成集合
fs _ index _ set=set(fs _ index)y3 _ index _ set=set(y3 _ index)y1 _ index _ set=set(y1 _ index)M6 _ index _ set=set(M6 _ index)m3 _ index _ set=set(m3 _ index)m1 _ index _ set=set(m1 _ index)
#成立以来一直在涨,涨了3年1年半3个月1个月
mix _ 6c=fs _ index _ set y3 _ index _ set y1 _ index _ set M6 _ index _ set m3 _ index _ set m1 _ index _ set print ' mix 6 c : ',mix_6cmix 6c: set([])
#好像没有东方不败,一直都是涨基金。有没有3年1年6个月3个月1个月一直涨的基金
mix _ 5c=y3 _ index _ set y1 _ index _ set M6 _ index _ set m3 _ index _ set m1 _ index _ set print ' mix 5c : ',mix _ 5c mix 5c 3360 set([150050,619,150124,110022])
哇,真的,我发现这四只基金才是真金,激动的老泪纵横~ ~稳健的投资者可以考虑这四只基金
3).1年以内的更佳基金
彼此比较亲近的投资者肯定会希望看到去年的所有数据
mix _ 4c=y1 _ index _ set M6 _ index _ set m3 _ index _ set m1 _ index _ set print ' mix 4c : ',mix_4cmix 4c: set([165312,150050,150149,110022,989,619,150124,169101,169102,169103,1712,1044,15024
#横向总结上面更好的基金,看哪个更好

165312 72.48150050 119.28150149 106.17110022 97.43989 78.04619 71.26150124 110.42169101 100.49169102 86.71169103 78.811712 76.71044 76.12150270 171.5150199 141.161112 88.05161725 88.0990 78.04
发现更好的基金150270一年涨了1.7倍多,太爽了。看名字
Fund _ id fund _ name一个月三个月六个月一年\ fund _ id 150050 150050南方消费激进21.42% 13.58% 22.58% 61.70%三年从_ start fund _ id 150050 270.26% 1999
原来,更好的基金是南方的积极消费
结论:
好了,今天的6500多篇基金数据分析文章先到了。其实数据分析很有意思。这个小项目完成了。以上对基金数据的分析只是冰山一角,还有很多地方需要探索和分析。基金投资,尤其是量化基金投资,涉及到很多方面和模式。最重要的是,基金选择只是步,如何买入,投资多少,如何建模降低风险,如何卖出等等都是非常讲究的。
相关文章
-
16
2021-06
-
16
2021-06
-
16
2021-06
-
16
2021-06
-
16
2021-06
-
16
2021-06
推荐阅读
随机推荐
- GZIP的工作原理分析
- dede文章导入数据库应该关联什么表呢?
- 降龙说说最近比较火的比特币吧
- 如何制作网站浏览器标签处的小图标(即ico图标)
- 2014即便失败了,也要再一次喝彩
- 网站设计中的连接问题
- 关闭Windows 2003/2008/2012“IE增强的安全配置”方法
- 使用Air实现Go程序实时热重载
- 使用cdn加载vue.js
- 使用CasperJS制作整个长网页截图工具
- 理解跨域异步请求的JSONP
- 比特币pow难度调节机制
- 微信小程序 自定义模态框
- 为什么一定要做中报行情
- dedecms pc站和移动站适配跳转代码
- 微信公众平台自动回复、关注等事件监听
- 在vue ELment-ui中解决错误报告问题
- 如何判断一个商城小程序制作公司的水平
- 在线客服系统用什么好?百度商桥有优势吗?
- 开通宝塔专业版对网站有什么优势?