使用requests爬取网页:Python网页解析库:用requests-html爬取网页
Python网页解析库:用requests-html爬取网页 1. 开始 Python 中可以进行网页解析的库有很多,常见的有 BeautifulSoup 和 lxml 等。在网上玩爬虫的文章通常都是
顺晟科技
2022-09-15 21:36:20
296
XPath (XML Path Language) 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。
W3School官方文档:http://www.w3school.com.cn/xpath/index.asp
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。
下面列出了最常用的路径表达式:
| 表达式 | 描述 | nodename 选取此节点的所有子节点。 / 从根节点选取。 // 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 . 选取当前节点。 .. 选取当前节点的父节点。 @ 选取属性。
|---|
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
| 路径表达式 | 结果 | bookstore 选取 bookstore 元素的所有子节点。 /bookstore 选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! bookstore/book 选取属于 bookstore 的子元素的所有 book 元素。 //book 选取所有 book 子元素,而不管它们在文档中的位置。 bookstore//book 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 //@lang 选取名为 lang 的所有属性。
|---|
谓语用来查找某个特定的节点或者包含某个指定的值的节点,被嵌在方括号中。
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
| 路径表达式 | 结果 | /bookstore/book[1] 选取属于 bookstore 子元素的第一个 book 元素。 /bookstore/book[last()] 选取属于 bookstore 子元素的最后一个 book 元素。 /bookstore/book[last()-1] 选取属于 bookstore 子元素的倒数第二个 book 元素。 /bookstore/book[position()<3] 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 //title[@lang] 选取所有拥有名为 lang 的属性的 title 元素。 //title[@lang=’eng’] 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 /bookstore/book[price>35.00] 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 /bookstore/book[price>35.00]/title 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。
|---|
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 | * 匹配任何元素节点。 @* 匹配任何属性节点。 node() 匹配任何类型的节点。
|---|
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 | /bookstore/* 选取 bookstore 元素的所有子元素。 //* 选取文档中的所有元素。 //title[@*] 选取所有带有属性的 title 元素。
|---|
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 | //book/title | //book/price 选取 book 元素的所有 title 和 price 元素。 //title | //price 选取文档中的所有 title 和 price 元素。 /bookstore/book/title | //price 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。
|---|
下面列出了可用在 XPath 表达式中的运算符:
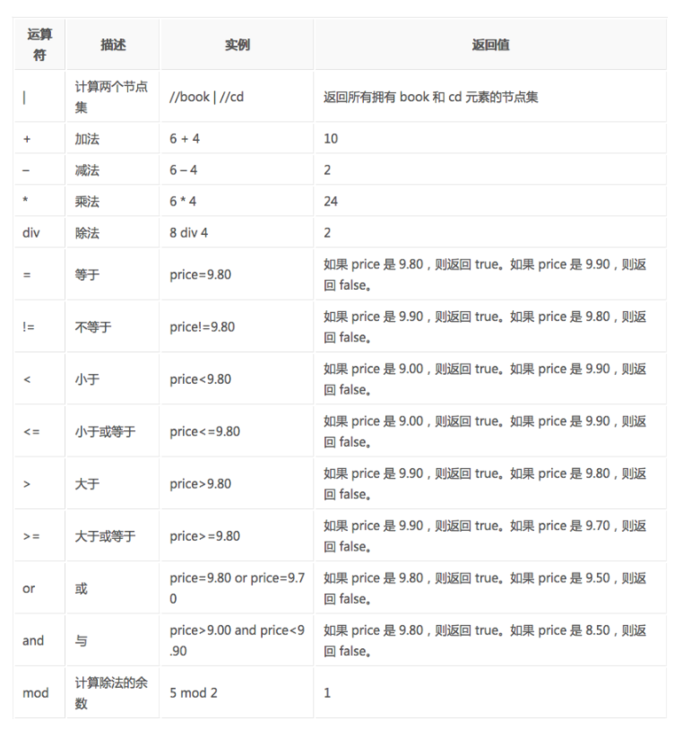
lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
lxml和正则一样,也是用 C 实现的,是一款高性能的 Python HTML/XML 解析器,我们可以利用之前学习的XPath语法,来快速的定位特定元素以及节点信息。
lxml python 官方文档:http://lxml.de/index.html
需要安装C语言库,可使用 pip 安装:
pip install lxml(或通过wheel方式安装)
我们利用它来解析 HTML 代码,示例1----------使用xpath的爬虫:
1 from urllib import request
2 import urllib.parse
3 from lxml import etree
4
5 #根据url发送请求,获取服务器响应文件
6 def loadPage(url):
7 # header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36"}
8
9 a=request.Request(url) # 奇怪,xpath无法解析出内容,结果为空。把headers去掉就好了,不知道为什么。
10 response=request.urlopen(a).read().decode(\'utf-8\')
11 # print(response)
12
13 # 解析HTML文档为HTML DOM模型
14 content=etree.HTML(response)
15 # 返回所有匹配成功的列表集合
16 link_list=content.xpath("//div[@class=\'t_con cleafix\']/div[2]/div/div[1]/a/@href")
17 # print(link_list)
18
19 for link in link_list:
20 print(\'正在获取url链接....\')
21 fulllink = "http://tieba.baidu.com"+link # 组合为每个帖子的链接
22 loadImage(fulllink)
23
24
25 # 取出每个帖子里的每个图片连接
26 def loadImage(link):
27 header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36"}
28 b=request.Request(link,headers=header)
29 response=request.urlopen(b).read().decode(\'utf-8\')
30
31 # 取出帖子里每层层主发送的图片连接集合
32 content1=etree.HTML(response)
33 link_list=content1.xpath("//img[@class=\'BDE_Image\']/@src")
34 # print(link_list)
35
36 for link in link_list:
37 print(\'正在获取图片链接....\')
38 wirteImage(link) # 取出每个图片的连接
39
40
41 #将图片写入到本地
42 def wirteImage(link):
43 header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36"}
44 c = request.Request(link, headers=header)
45 image = request.urlopen(c).read() # 图片原始数据
46 # print(image)
47 filname=link[-10:] # 取出连接后10位做为文件名
48 print(\'正在保存图片....\')
49 with open(r\'E:\python_practice_ku\pachong\1\\\'+filname,\'wb\') as f:
50 f.write(image)
51
52
53 #贴吧爬虫调度器,负责组合处理每个页面的url
54 def tiebaSpider(url,kw, beginPage, endPage):
55 data = {\'kw\': kw}
56 data = urllib.parse.urlencode(data)
57
58 for page in range(beginPage,endPage+1):
59 fullurl = url + data+"&ie=utf-8" + "&pn=" +str(page)
60 loadPage(fullurl)
61
62
63 if __name__ == \'__main__\':
64 kw = input("请输入需要爬取的贴吧名:")
65 beginPage = int(input("请输入起始页:"))
66 endPage = int(input("请输入结束页:"))
67
68 url = \'https://tieba.baidu.com/f?\'
69 tiebaSpider(url,kw,beginPage,endPage)
示例2
1 from urllib import request
2 from lxml import etree
3 import json
4
5 url=\'http://www.waduanzi.com/\'
6 header={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36"}
7
8 a=request.Request(url,headers=header)
9 response=request.urlopen(a).read().decode(\'utf-8\')
10
11 # 响应返回的是字符串,解析为HTML DOM模式 text = etree.HTML(response)
12 text=etree.HTML(response)
13 # 返回所有段子的结点位置,contains()模糊查询方法,第一个参数是要匹配的标签,第二个参数是标签名部分内容
14 node="//div[contains(@class,\'panel panel20\')]"
15 node_list=text.xpath(node)
16 # print(node_list)
17
18 for node in node_list:
19 # xpath返回的列表,这个列表就这一个参数,用索引方式取出来,用户名
20 img = node.xpath("./div[1]/img/@src")[0]
21 title = node.xpath("./div[2]/h2/a/@title")[0]
22 # 取出标签下的内容,段子内容
23 # content = node.xpath("./div[2]/div")[0].text //遇到有 和<br>后,文本内容没有取全
24 content = node.xpath("normalize-space(./div[2]/div)") #normalize-space()遇到有 和<br>后,文本内容正常取
25 zan = node.xpath("./div[3]/ul/li[1]/a")[0].text
26 buzan = node.xpath("./div[3]/ul/li[2]/a")[0].text
27
28 items={
29 "img": img,
30 "title":title,
31 "content":content.replace("\xa0",""),
32 "zan":zan,
33 "buzan":buzan,
34 }
35
36 # print(items)
37 with open(\'waduanzi.json\',\'a\') as f:
38 f.write(json.dumps(items,ensure_ascii=False)+",\n")
39
40 with open(\'waduanzi.json\',\'r\') as f1:
41 print(f1.read())
<li> 标签# xpath_li.py
from lxml import etree
html = etree.parse(\'hello.html\')
print type(html) # 显示etree.parse() 返回类型
result = html.xpath(\'//li\')
print result # 打印<li>标签的元素集合
print len(result)
print type(result)
print type(result[0])
输出结果:
<type \'lxml.etree._ElementTree\'>
[<Element li at 0x1014e0e18>, <Element li at 0x1014e0ef0>, <Element li at 0x1014e0f38>, <Element li at 0x1014e0f80>, <Element li at 0x1014e0fc8>]
5
<type \'list\'>
<type \'lxml.etree._Element\'>
<li> 标签的所有 class属性# xpath_li.py
from lxml import etree
html = etree.parse(\'hello.html\')
result = html.xpath(\'//li/@class\')
print result
运行结果
[\'item-0\', \'item-1\', \'item-inactive\', \'item-1\', \'item-0\']
<li>标签下hre 为 link1.html 的 <a> 标签# xpath_li.py
from lxml import etree
html = etree.parse(\'hello.html\')
result = html.xpath(\'//li/a[@href="link1.html"]\')
print result
运行结果
[<Element a at 0x10ffaae18>]
<li> 标签下的所有 <span> 标签# xpath_li.py
from lxml import etree
html = etree.parse(\'hello.html\')
#result = html.xpath(\'//li/span\')
#注意这么写是不对的:
#因为 / 是用来获取子元素的,而 <span> 并不是 <li> 的子元素,所以,要用双斜杠
result = html.xpath(\'//li//span\')
print result
运行结果
[<Element span at 0x10d698e18>]
<li> 标签下的<a>标签里的所有 class# xpath_li.py
from lxml import etree
html = etree.parse(\'hello.html\')
result = html.xpath(\'//li/a//@class\')
print result
运行结果
[\'blod\']
<li> 的 <a> 的 href# xpath_li.py
from lxml import etree
html = etree.parse(\'hello.html\')
result = html.xpath(\'//li[last()]/a/@href\')
# 谓语 [last()] 可以找到最后一个元素
print result
运行结果
[\'link5.html\']
# xpath_li.py
from lxml import etree
html = etree.parse(\'hello.html\')
result = html.xpath(\'//li[last()-1]/a\')
# text 方法可以获取元素内容
print result[0].text
运行结果
fourth item
class 值为 bold 的标签名# xpath_li.py
from lxml import etree
html = etree.parse(\'hello.html\')
result = html.xpath(\'//*[@class="bold"]\')
# tag方法可以获取标签名
print result[0].tag
运行结果
span
30
2022-09
25
2022-09
15
2022-09
15
2022-09
15
2022-09
15
2022-09